Fixing Sticky Session Management Issues: Consistent Hashing and Layered Reverse Proxy Approach
- NOURA ALSHAREEF
- Oct 21, 2023
- 4 min read

My team and I usually develop web-apps through a commonly-used partitioned strategy with an isolated REST API backend application-server that handles HTTP requests from a front-end web-server, usually served through Nginx.
My web-app uses browser-cookie based user-authentication, handled by the application-server. The cookie value is mapped to an object that holds all information about the user. This information is calculated the first time the user logs in, and subsequent requests should be passed to the same application server node that served the user's first request, so that there is no need to collect the user info again. This requires the user session to be sticky.
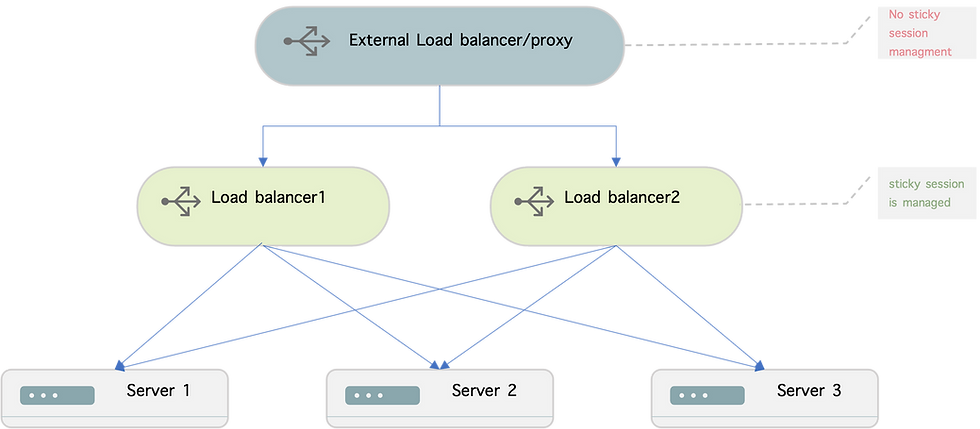
Our architecture consists of two web-apps/load balancers (Nginx) and three application servers. However, we encountered a problem where there was an extra layer of load balancer before the request reached the web-app. This external load balancer randomly distributed incoming requests across the web-apps/load balancers, resulting in subsequent requests from the same user being sent to different web-apps/load balancers. Since both web-apps/load balancers were using the same method of obtaining the session ID from the request header and mapping it to a specific application server, and both of them have the same set of application servers; we didn't encounter any problems. However, when one of the servers went down, we unfortunately experienced an issue! all the requests were redistributed to different servers, not only those who belonged to the down server, but also most of other servers' . This caused the loss of user session data and resulted in users being unexpectedly logged out of the web-app.
We attempted to communicate with the extra load balancer team to configure it to use sticky sessions, but based on their policy, they were unable to make any changes to the load balancer. This left us in a situation where we needed to find a solution that worked within our existing infrastructure.
After considering various possibilities such as eliminating the sticky session and storing all user-session-info on a shared database, or altering the load-balancing algorithm at the web-app level, we arrived at a solution which consider theses important points :
First, we need a mechanism where if one of the application servers is down, no whole redistribution happens, but only the effected ones.
Second, if an application server is not reachable by one load balancer but is reachable by another, the sticky session directing formula should ensure that requests are directed to the same available servers regardless of the difference of pool size of the load balancers.
To achieve the first point, We delved into the hashing mechanisms finding that consistent hashing very suitable in our case. it's explained previously at NoraTech. Also you can find the hashing implementation for Nginx and HAProxy.
The second point posed a challenge, which can be illustrated through the following scenario: Suppose requests with keys (in this case, client IPs) R1, R2, and R3 go to AppServer1; R4, R5, and R6 go to AppServer2; and R7, R8, and R9 go to AppServer3.
If AppServer3 suddenly becomes unresponsive to Load-balancer1, but is still reachable by Load-balancer2, the consistent hashing algorithm will direct the corresponding requests to the next larger hash, let say AppServer1.
As a result, requests R7, R8, and R9 that are coming through Load-balancer1 will be directed to AppServer1, while those coming through Load-balancer2 will continue to be directed to AppServer3. This means that there is a 50% chance that a user will be logged out when the next request with key R7 is received. This applies not only to users who logged in before the connectivity issue arose between Load-balancer1 and AppServer3, but also to current and future users until the issue is resolved.
The issue described occurred because the requests were not tied to either Load-balancer 1 or Load-balancer 2. To address this issue, the concept of a Layered Reverse Proxy was considered as a possible solution.
Layered Reverse Proxy
A layered reverse proxy involves the use of multiple layers of reverse proxies to manage incoming requests and distribute them to backend servers. Each layer of the proxy is responsible for a specific function.
In the case of the issue described, a layered reverse proxy could be used to ensure that requests are always directed to the same load balancer.
To achieve this, the first layer of the proxy - either Load-balancer1 (LB1) or Load-balancer2 (LB2) - would be configured to perform load balancing between the two load balancers. Consistent hashing would be used to determine whether the request should be directed to LB1 or LB2 based on the request key (e.g. client IP).
Once the request is directed to either LB1 or LB2, another consistent hashing operation would be performed to determine which application server should receive the request.
From there, the Layered Reverse Proxy would ensure that the request is consistently directed to the same load balancer and application server, regardless of any changes in the backend infrastructure.
The figure illustrates one possible path that a client request takes from the client's device to the backend servers

Here is an example implementation of an Nginx configuration that incorporates Layered Reverse Proxy and consistent hashing in http block at LB1:
http {
upstream backend_servers {
hash $remote_addr consistent;
server appserver1.example.com;
server appserver2.example.com;
server appserver3.example.com;
}
upstream load_balancers {
hash $remote_addr consistent;
server lb1.example.com;
server lb2.example.com;
}
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://load_balancers;
proxy_connect_timeout 2s;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_next_upstream error timeout invalid_header http_502 http_503 http_504;
}
}
server {
listen 80;
server_name lb1.example.com;
set_real_ip_from 127.0.0.1;
real_ip_header X-Real-IP;
real_ip_recursive on;
location / {
proxy_pass http://backend_servers;
}
}
}In this configuration, the upstream directive is used to define two upstream groups: backend_servers and load_balancers. The hash parameter is used in the backend_servers group to implement consistent hashing based on the client's IP address.
The server block defines a virtual server for handling HTTP requests. The location blocks are used to define how requests to different URLs should be handled. In this case, requests to example.com are passed to the load_balancers group, while requests to the lb1.example.com are passed to the backend_servers group.
Overall, this configuration demonstrates how Nginx can be used to implement a Layered Reverse Proxy with consistent hashing to improve the reliability and availability of web applications.
I hope you enjoyed this article and found it informative ♡



Hozzászólások